Good Times
Over a decade ago I realized my eating patterns, lack of exercise, and long work hours was a problem. In fairness, this conclusion came because my physician at the time thought it would be a good idea for me to start taking blood pressure and cholesterol medication in my mid 20s.
“Is there anything else I could do?” I asked. He said “Well, diet and exercise.” I thought for a few moments and noted “OK, I’d like to do that.” I could tell he wasn’t a fan of my response but agreed stating that if numbers didn’t get better in 6 months he’d like me to start the medications.
I cut out soda, started to pay attention to serving sizes, and found some exercise that I could enjoy (simple recreational bicycling). Just 6 months in and I had visibly lost weight and the tests showed my blood pressure and cholesterol were in good shape.
“No one actually makes diet or exercise changes, that’s why I wasn’t hopeful anything would change.” stated my doctor. We were both happy with the result and no medication was needed. It really was a positive feeling and kicked off a journey to see how I could get even healthier.
Over the next couple years I worked hard modifying my diet, increasing exercise, and getting my life/work balance in check. I slowly lost weight and gained some muscle. At some point I hit a plateau but I was happy where I was. I took up Muay Thai, cycled to work most days, things were great….until I started to have this pain I couldn’t really explain.
It Hurts When I …
It was weird. Very weird. The pain was in my back, but on the side. Deep inside but near the edge. Maybe my hip? As you can imagine it was tough to describe. Here is roughly what was assumed before some kind of intestinal issue was looked at:
- Stomach infection
- Herniated disc
- Kidney stones
- Hernia
- Reproductive issues (seriously…)
During this time I started to rapidly lose healthy weight and muscle. I had dropped from a good body composition in the 170s down to 150s.
Then came the referral to a GI specialist. After getting scoped it was apparent I had ulcerative colitis. The news came about a week after the procedure. Hearing the words Ulcerative Colitis was scary as this was something I had never heard of before. The nurse practitioner was extremely helpful and kept me calm while explaining the diagnosis. At the time she decided to start me on a medicine called Lialda (Mesalamine).
Did It Work?
Heck yeah it did! I took 2 monster pills every morning. The result was less pain and less running to the bathroom. Though it started to be less effective after about a year. We bumped it up untill we maxed out the dosage and things once again got better but then started to get worse. Like way worse.
It Can Always Be Worse
I started running to the bathroom more often…and I mean running. It went from 5-7 times a day to multiple times an hour. Of course this kept me from going places for fear of not getting to a bathroom in time in public (which happened by the way…). I started to have very little energy and weight continued to fall off even though my diet didn’t change (though exercise was less). I went from lean 150s to 130s. For my body this meant my ribs and sternum were visible at all times and I was able to fully grab hold of my ribcage from underneath. That’s not good.
Obviously Lialda wasn’t cutting it anymore.
Quick Aside
It may sound silly but I was very worried people would discount the work I did to go from just under 300 pounds to 170 thinking it was because of my condition. I knew I had put in a lot of time and work to get my weight down and my health up. This, in part, was one reason I didn’t share what I had gone through with many people.
Stronger Drugs
After speaking with my awesome nurse practitioner we decided to look at 6mp (Mercaptopurine). Before starting 6mp it was important for me to get more tests done to ensure I was healthy enough to handle the side effects. It was here a test found something strange while x-raying my chest.
“Do you smoke Mr. Milner?’
“I’ve never smoked anything. Why?”
“OK, we need to do some more scans.”
I came back another day and they scanned with another kind of machine (CT I believe). They noted they can see pretty big spots in my lungs. Well, switching meds wasn’t an option until these spots get figured out. Spots became masses. 3 to be specific.
Let’s Take A Closer Look
Here is a quick explanation of what came next. Another contrast CT. Next came a needle biopsy through my back to get to the lung. Then came surgery to remove a portion of the mass for review as nothing so far could explain what these masses were. During this time cancer was an expected possibility. Thankfully after the surgery (and a few weeks waiting on Mayo Clinic) it was found to be a rare condition called BOOP.
I had the BOOP.
Seriously. Sounds like something a clown catches.
I was immediately taken off Lialda and put on a massive amount of Prednisone. 60mg a day for a while and then taper down for 6 months. That did resolve the BOOP and “helped” with the UC. After that I was able to switch to 6mp without issue.
Now
I still take 6mp and it really does seem to help. It’s not a miracle drug but it’s still something I’m happy is available. It would be insincere to say that I don’t have pain daily. Some days I’m beyond exhausted. Anemia comes and goes. Arthritis? Yeah, especially in weather changes.
But with all that I’m still in a way better place than before! The Internet had been a super helpful place to learn about what helps others with the condition. For me these items have been quite helpful:
- Taking the medicines prescribed 🙂
- Hot epsom salt baths
- Mediation and/or de-stressing
- Limiting or eliminating caffeine and alcohol
- Reducing usable carb intake (a surprising but effective positive change for me)
- Exercise

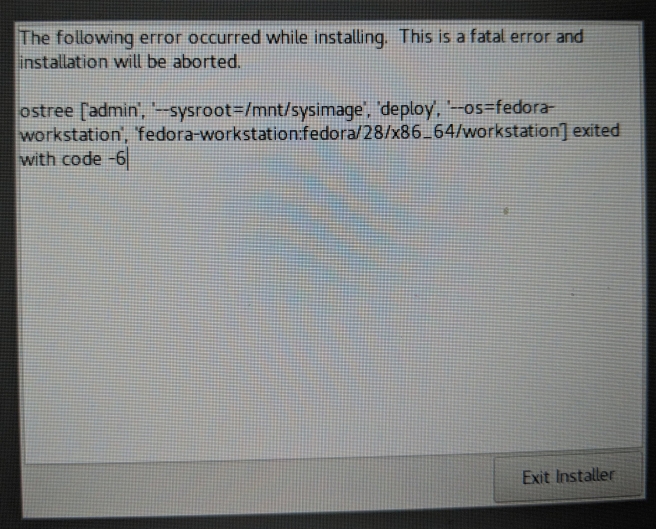


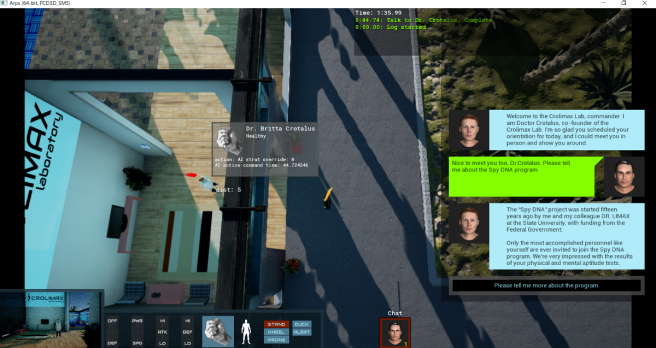 The lab demo takes you through a bit of the story. I talked with a number of folks working at the lab and learn what the lab is for, the history of the organization, and what I would be doing for them. I ended up using this area to get used to the controls. One thing that got me over and over was the camera movement. I kept wanting to use WASD to move the camera with Q and E to rotate. I’m not sure why I kept gravitating towards those bindings but, for me, they would make more sense than the arrow keys. In any case I’m sure Shy Snake will either add similar bindings or will be able to explain why the arrow keys make more sense for Spy DNA.
The lab demo takes you through a bit of the story. I talked with a number of folks working at the lab and learn what the lab is for, the history of the organization, and what I would be doing for them. I ended up using this area to get used to the controls. One thing that got me over and over was the camera movement. I kept wanting to use WASD to move the camera with Q and E to rotate. I’m not sure why I kept gravitating towards those bindings but, for me, they would make more sense than the arrow keys. In any case I’m sure Shy Snake will either add similar bindings or will be able to explain why the arrow keys make more sense for Spy DNA.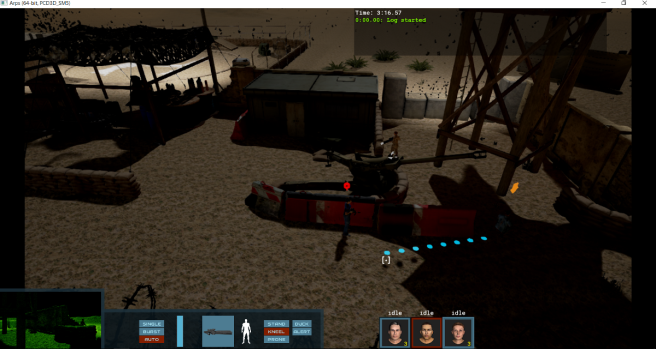 In the outdoor combat demo you get a three member squad and are faced with an encampment of enemies keeping patrol. For some reason one of the members always started far off the screen, but this is pre-alpha after all! In any case, this is where the fun really begins! I was able to sneak in and around a few guards before needing to start taking out some of them. By default you move quickly from point to point but, by clicking and holding, you can change how you traverse terrain allowing for sneaking and other options.
In the outdoor combat demo you get a three member squad and are faced with an encampment of enemies keeping patrol. For some reason one of the members always started far off the screen, but this is pre-alpha after all! In any case, this is where the fun really begins! I was able to sneak in and around a few guards before needing to start taking out some of them. By default you move quickly from point to point but, by clicking and holding, you can change how you traverse terrain allowing for sneaking and other options.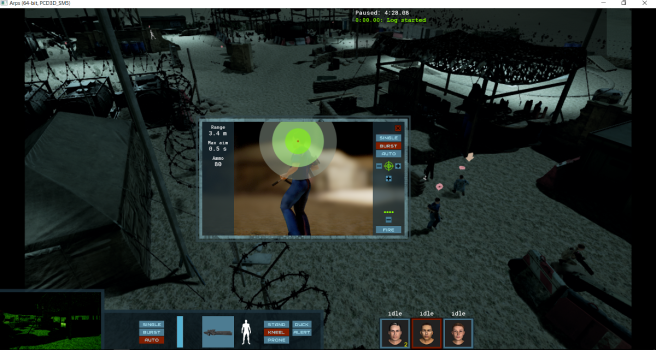
 Since
Since  Another child of the original Alan Scott,
Another child of the original Alan Scott,  Prophesied to be the last of the Green Lanterns in the future, and an important host to Ion, Sodam Yat has been
Prophesied to be the last of the Green Lanterns in the future, and an important host to Ion, Sodam Yat has been  Also known as Cyborg Superman. You remember, one of the 4 Supermen that came to be after Superman “died”. Hank is one of the more interesting thorns in the Lanterns side yet has been pretty absent since the reboot even though
Also known as Cyborg Superman. You remember, one of the 4 Supermen that came to be after Superman “died”. Hank is one of the more interesting thorns in the Lanterns side yet has been pretty absent since the reboot even though 
 ne I really took notice of, but without having a legacy to stand on his character is a bit boring. Not only that, but in the past the scarab has been noted as a weapon of the Reach (an enemy of
ne I really took notice of, but without having a legacy to stand on his character is a bit boring. Not only that, but in the past the scarab has been noted as a weapon of the Reach (an enemy of 